Disclaimer: The notes are made from information available here and wikipedia.
Conjugate gradient is effective for solving systems of the form:


The CG method is most effective in solving systems where
Now, say we are finding the optimal solution of a quadratic equation 
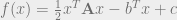
For a positive definite square symmetric matrix 

So why use CG?
The idea is to solve the equation not by finding the intersection of hyperplanes rather, by iterative minimization of the problem.
Method of Steepest Descent
The method of steepest descent entails starting from an arbitrary point 
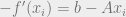
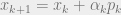
Where 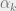
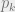
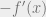
As error 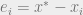

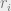
Eigenvectors and Eigenvalues
Eigenvector 


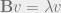
Spectral radius: 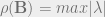
Jacobi iterative method
In pursuit of solving 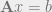
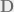

for, 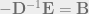

Now, at the optimal point, 

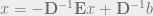

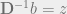
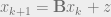
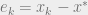
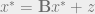
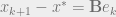
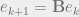
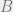 is not the eigenvector of . How does it still converge the results? can be split as a sum of eigenvectors of .
is not the eigenvector of . How does it still converge the results? can be split as a sum of eigenvectors of .

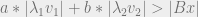
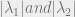 are smaller than one, the value of LHS reduces with every increment hence converging the value of
are smaller than one, the value of LHS reduces with every increment hence converging the value of 
b) This is an arbitrary choice with the hope to get
Now, splitting 
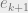

Convergence
is in the direction of eigenvector,  using steepest descent the optimal point is reached at one attempt.
using steepest descent the optimal point is reached at one attempt. can be broken further into its eigenvector components. If we take all eigenvector of such that their eigenvalues are same then the optimal solution is reached in one step (Spherical rather than ellipsoidal cross-section) but in case of several non equal eigenvalues, the convergence gets tough.
can be broken further into its eigenvector components. If we take all eigenvector of such that their eigenvalues are same then the optimal solution is reached in one step (Spherical rather than ellipsoidal cross-section) but in case of several non equal eigenvalues, the convergence gets tough.REVIEW
So, Steepest Descent algorithm is rougher, this is not the most efficient way while Jacobi method is smoother because every eigenvector component is reduced in every iteration.
The Method of Conjugate Directions
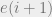 is A-orthogonal to
is A-orthogonal to  :
: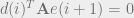

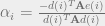
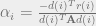 is the search direction.
is the search direction.