Lagrange multipliers 
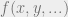
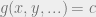


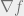
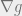
The process can thereby be condensed to finding the solution of gradient of a Lagrangian function 


Image courtesy: Khan academy
A bit of everything
Lagrange multipliers
The process can thereby be condensed to finding the solution of gradient of a Lagrangian function
Image courtesy: Khan academy
AVO stands for Amplitude Versus Offset, it gives the relationship between the seismic reflection coefficient at a point based on different distances between the source and receivers. AVO analysis can be used to know more about the rock properties.
Reflectivity coefficient 

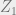
Mathematical
Zoeppritz equation
RP, RS, TP, and TS, are the reflected P, reflected S, transmitted P, and transmitted S-wave amplitude coefficients, respectively, 


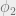
Shuey
As Zoeppritz equation gave no further intuitive explanation to this behaviour, Shuey (with inspiration from Ostrander’s work) explained the angular dependance of the refection coefficient using the Poisson’s ratio (in case of the shear wave terms, for acoustic term it only depends on the impedance and the angle of reflection). We have a 3-term Shuey equation:
where,
R(0) is the reflectivity coefficient for normal incidence. G is the AVO gradient, that gives the relation of reflection coefficient with different offset and F describes behaviour at large angles, closer to critical angles. If we make the incidence angle smaller than 30 degrees, the third term approaches 0, making this equation simpler to a 2-term Shuey approximation. If we ignore the S wave conversion and keep it to P-P waves, it becomes even simpler:
AVO crossplots
These are used to plot the relationship between the different amplitudes in a common image gather to give the gradient. Instead of averaging via stacking, this helps to get more information about the rock properties. Ideally the amplitude decreases with increase in offset, because of geometrical spreading. However, AVO anomaly is seen where the amplitude increases with increasing offset due to a softer layer (often a hydrocarbon reservoir).
Continue reading “Amplitude Variation with Offset or Angle (AVO/AVA)”
The animations below show the incident, reflected, transmitted, and total fields, over the course of a cycle, both for normal refraction,




and for total internal reflection:





I will try to enlist as many tutorials I find in this post!
This is a continuation of my notes on MPI. The last two notes on MPI tutorials are here and here. The references have been listed in Part 1 and 2 of the notes.
MPI defines its primitive data types. For example: MPI_CHAR/ MPI_FLOAT/ MPI_C_FLOAT_COMPLEX etc. But MPI also lets you define your own data structure based on MPI primitive data types. MPI provides several methods for constructing derived data types:
MPI_Type_contiguous : The simplest constructor. Produces a new data type by making count copies of an existing data type.

MPI_Type_vector : Similar to contiguous, but allows for regular gaps (stride) in the displacements. MPI_Type_hvector is identical to MPI_Type_vector except that stride is specified in bytes.
| MPI_Type_vector (count,blocklength,stride,oldtype,&newtype) |

MPI_Type_indexed : An array of displacements of the input data type is provided as the map for the new data type.
| MPI_Type_indexed (count,blocklens[],offsets[],old_type,&newtype) |

MPI_Type_struct/MPI_Type_create_struct : The new data type is formed according to completely defined map of the component data types.
| MPI_Type_struct (count,blocklens[],offsets[],old_types,&newtype) M |

https://computing.llnl.gov/tutorials/mpi/#Group_Management_Routines
https://computing.llnl.gov/tutorials/mpi/#Virtual_Topologies
I have taken notes from different sources (mentioned at the end of this article). The first part will cover the basics of MPI.
MPI stands for Message Passing Interface. MPI primarily addresses the message-passing parallel programming model: data is moved from the address space of one process to that of another process through cooperative operations on each process. It is not a language but just a library of functions.
Some familiar kinds of Message Passing Interface: Watsapp and Twitter
MPI buffers are data packet that transfer information between the sender and the receiver.
Memory Pipes (MPI) are memory-based structures used for communicating between the Internet Communication Manager and work processes. They are used to transfer the data packets between the sender and receiver.
Compilers used for MPI: mpicc, mpif90 etc.
Compilation looks like this:
$ mpicc -o prog prog.c
Running mpi code:
$ mpirun -np <no_of_processors> <prog_name>
$ srun -p SHARED -n<no_of_processors> -N<no_of_cores> –mpi=pmi2 <prog_name>

Example 1:
#include <mpi.h> #include <stdio.h> int main(int argc, char** argv) { // Initialize the MPI environment MPI_Init(&argc, &argv); // Get the number of processes int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); // Get the rank of the process int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); // Get the name of the processor char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); if (world_rank == 0) { // Print off a hello world message with process name only if rank is 0 printf("Hello world from processor %s, rank %d out of %d processors\n",processor_name, world_rank, world_size); } else { // Print off only the hello world message printf("Yello world from processor %s, rank %d out of %d processors\n",processor_name, world_rank, world_size); } // Finalize the MPI environment. MPI_Finalize(); }
MPI calls begin with MPI_xxx in C.
Initialisation:
Communicators or groups:
MPI uses objects called communicators and groups to define which collection of processes may communicate with each other. Among themselves they have ranks and they communicate with each other according to their ranks. Most MPI routines require you to specify a communicator as an argument. Use MPI_COMM_WORLD whenever a communicator is required – it is the predefined communicator that includes all of your MPI processes.
Ranks:
When you execute your code, using
“srun -p SHARED -n4 -N2 –mpi=pmi2 ./helloworld” ;
Hello world from processor node14, rank 0 out of 4 processors
Yello world from processor node14, rank 1 out of 4 processors
Yello world from processor node15, rank 2 out of 4 processors
Yello world from processor node15, rank 3 out of 4 processors
Remember, that all processes will run the same code, and so when they print hello world from such and such a rank, it will be executed multiple times in a row, and it will have multiple hello world statements. This is an example of how you can use the rank to differentiate the work between processes. If the rank is ranked number 0, then I will print hello world size, so only one process will execute this print size statement.
Next part of the notes is here.
Most of the modeling we do requires linear operations that predict data from models. However, in Imaging, the usual task is to find inverse of these operators to find the models from the data. This is where the Adjoint operator comes to rescue as a part of the inversion process.
Adjoint of a matrix is simply the complex-conjugate transpose of the same matrix.
Sometimes, the adjoint does a better job than the inverse as the adjoint operator tolerates imperfections in the data and does not demand the data to provide full information.
For a system defined by 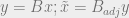


Convolution:
(Adjoint) Cross-correlation:
Causal integral: A causal operator is one that uses its present and past inputs to make its current output. Causal operators are generally associated with lower triangular matrices and positive powers of Z.
(Adjoint) Anticausal: Anticausal operators use the future but not the past. Anticausal operators are associated with upper triangular matrices and negative powers of Z.
An intuitive approach:
Two part in-depth description:
Use of SVD in finding pseudo inverse of a matrix:
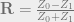




 ;
;











